
# Threads, Processes Trong Python (Phần 2)
Ở bài viết trước, mình đã trình bày khá nhiều về threading trong Python. Với threads, ta đã biết nó sẽ bị ảnh hưởng bởi GIL và chỉ phù hợp cho các tác vụ nặng về xử lý I/O.
Nhưng khi làm việc với các tác vụ nặng về tính toán, đòi hỏi phải tận dụng các lõi CPU thì chúng ta sẽ chạm tới một chủ đề con khác.
Bài này ta sẽ cùng tìm hiểu processes trong Python nó là gì.
Processes.
Processes nghĩa là tiến trình là một thực thể (instance) của chương trình, khác với luồng (threads) nó không bị ảnh hưởng bởi GIL. Mỗi khi spawn ra một process mới, mỗi process đó sẽ có một GIL của riêng mình.
Một process có thể có một hay nhiều threads bên trong nó.
Nó giúp cho hệ thống tối ưu hóa tài nguyên của mình, có thể dùng nhiều core CPU tại một thời điểm. Do đó, nó tốn nhiều chi phí tài nguyên hơn
Ta có thể chia sẻ thông tin giữa các process thông qua giao thức IPC, nhưng nó chậm hơn việc share giữa các threads. Các processes không share không gian bộ nhớ với nhau.
Trong Python, chúng chia sẻ thông tin bằng việc dùng các cấu trúc dữ liệu như arrays.
Giờ chúng ta sẽ tìm hiểu thư viện multiprocessing trong Python. Với multiprocessing, Python sẽ tạo ra các processes mới. Các processes này
sẽ được phân phối lên từng lõi CPU.
Để hiểu tác dụng của multiprocessing, ta sẽ xét chương trình thực thi tuần tự trước.
Synchronize.
Xét ví dụ:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
Đoạn code trên thực thi trên 1 thread và 1 process duy nhất trên 1 CPU đơn. Có thể biểu diễn theo hình sau:
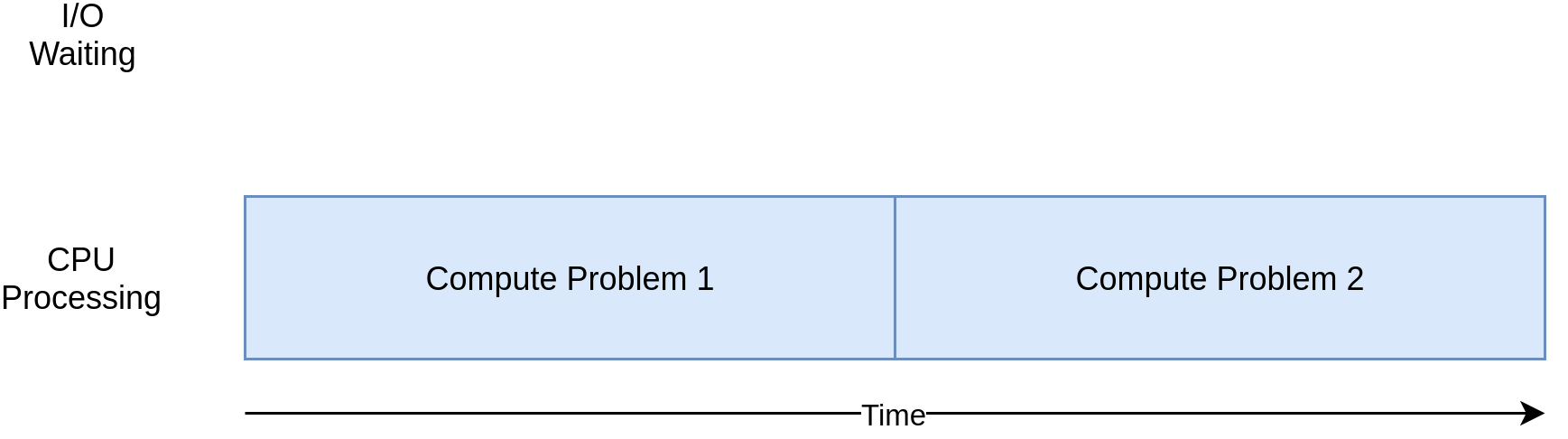
Đây là kết quả của đoạn code trên:
./non_concurrent.py
Duration 7.834432125091553 seconds
multiprocessing.
Viết lại ví dụ trên:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 * x for x in range(3)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
multiprocessing được thiết kế để share khối lượng công việc nặng về tính toán giữa các CPUs. Đây là biểu đồ thực thi của chương trình theo thời gian:
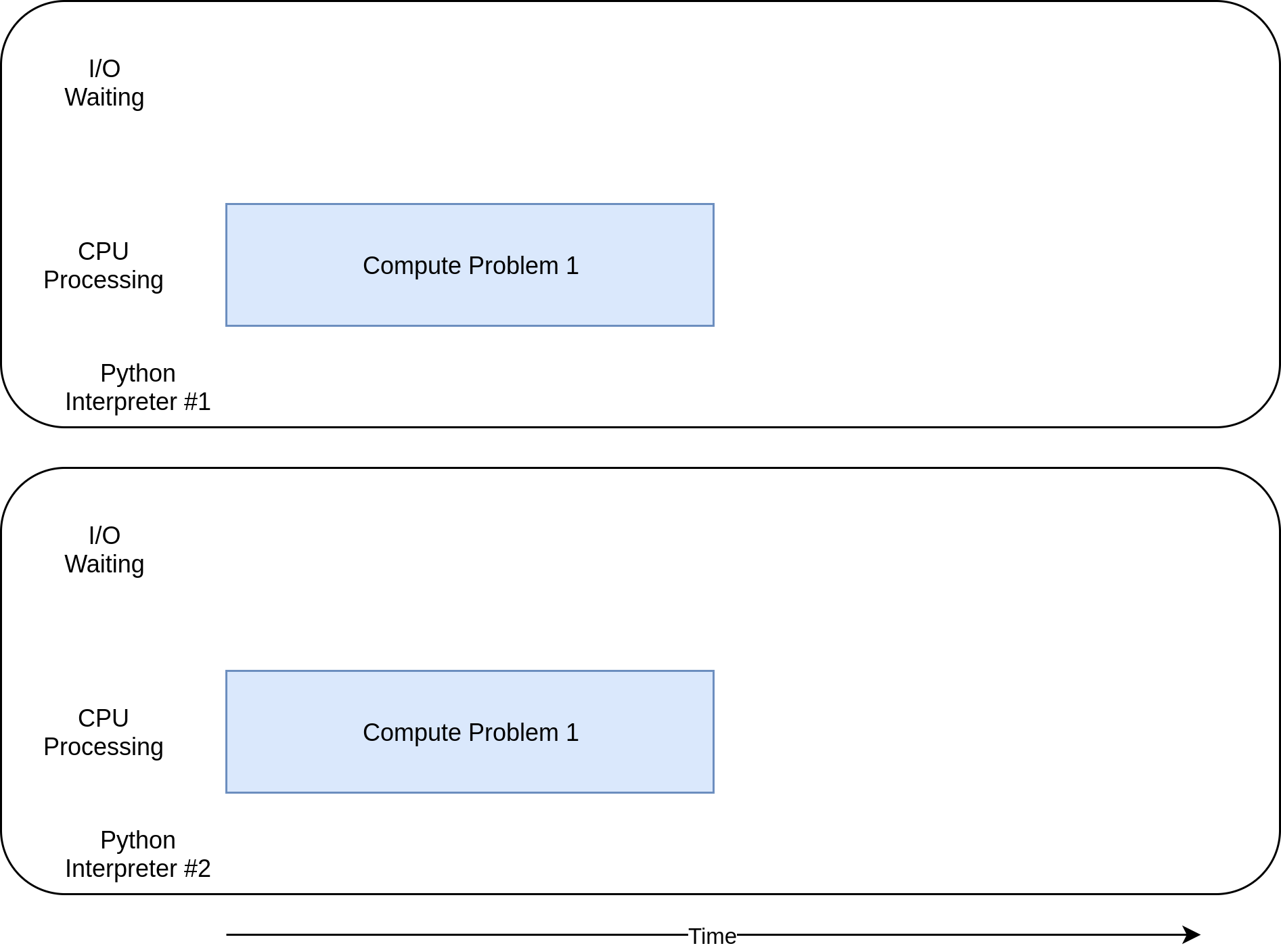
Mặc định, khi tạo ra processes mới. Nó sẽ tự động xác định xem hệ thống của bạn có tối đa bao nhiêu CPUs. Có thể hình dung cách hoạt động của nó theo hình sau:

Ở đây, mỗi thread sẽ nằm trên mỗi processes.
Sau khi chạy, kết quả thu được sẽ là:
./test_multiprocessing.py
Duration 2.5175397396087646 seconds
Nó nhanh hơn gần gấp 3 lần.
ứng dụng multiprocessing.
Như đã trình bày, multiprocessing sẽ phù hợp với các tác vụ nặng về tính toán. Bởi lúc này ta cần tận dụng tối đa hiệu năng của CPU trên máy tính.
Nếu sử dụng threading hay concurrent.futures.ThreadPoolExecutor trong trường hợp này không mang nhiều ý nghĩa do chúng ta sẽ không mất thời gian đợi I/O phản hồi.
Dùng threads thì sẽ bị ảnh hưởng của GIL, nên cho dù có là chương trình đa luồng thì vẫn sẽ chạy như chương trình đơn luồng.
Với multiprocessing, mỗi process sẽ có một interpreter (một GIL). Nên lúc này chương trình của bạn sẽ chạy các tác vụ được phân phối đều trên các lõi CPUs.
Trong thư viện multiprocessing của Python, có 2 classes bạn nên lưu tâm là Process và Pool.
Process class gửi mỗi task tới các lõi CPU khác nhau.
Pool class gửi tập hợp các task tới các lõi CPU khác nhau.
Mặc dù 2 classes cung cấp một tốc độ thực thi tương tự. Process class lại hiệu quả hơn trong trường hợp không có quá nhiều processes cần thực thi. Trong khi Pool class thì lại phù hợp nhất với một lượng lớn các processes nơi mà mỗi process có thể thực thi một cách nhanh chóng.
Bạn có thể tìm hiểu sâu hơn về multiprocessing tại đây.
Bonus, còn một chỗ đáng lưu tâm là khi sử dụng multiprocessing, khi nào nên sử dụng fork, khi nào sử dụng spawn để tránh chương trình bị kẹt (stuck).
Mình có đọc 1 bài viết rất hay về vấn đề này. Ngoài ra còn bài của Dr John A Stevenson.
fork và spawn là 2 phương thức bắt đầu tạo processes mới. Fork mặc định trên Linux, trong khi Windows và MacOS dùng Spawn.
Khi fork, một process con kế thừa các biến, module-level configurations, threads và trạng thái của các biến như nhau từ process cha. Mỗi process con sau đó tiếp tục công việc của chúng 1 cách độc lập, pool sẽ chia các args giữa các process con và chúng hoạt động một cách tuần tự.
Khi spawn, nó bắt đầu một Python interpreter mới. Các modules hiện tại trong chương trình được imported lại cho mỗi process con, các biến cũng thế. Sau đó, mỗi hàm thực thi trong process sẽ được gọi trên mỗi args được cấp cho process con đó.
Để hiểu hơn, ta đi vào các đoạn code ví dụ sau:
from multiprocessing import Pool
from os import getpid
def double(i):
print("I'm process", getpid())
return i * 2
if __name__ == '__main__':
with Pool() as pool:
result = pool.map(double, [1, 2, 3, 4, 5])
print(result)
Kết quả là:
I'm process 4942
I'm process 4943
I'm process 4944
I'm process 4942
I'm process 4943
[2, 4, 6, 8, 10]
Hàm double chạy trong 5 processes.
Ví dụ tiếp theo, gọi là ví dụ 1:
import logging
from threading import Thread
from queue import Queue
from logging.handlers import QueueListener, QueueHandler
from multiprocessing import Pool
def setup_logging():
# Logs get written to a queue, and then a thread reads
# from that queue and writes messages to a file:
_log_queue = Queue()
QueueListener(
_log_queue, logging.FileHandler("out.log")).start()
logging.getLogger().addHandler(QueueHandler(_log_queue))
# Our parent process is running a thread that
# logs messages:
def write_logs():
while True:
logging.error("hello, I just did something")
Thread(target=write_logs).start()
def runs_in_subprocess():
print("About to log...")
logging.error("hello, I did something")
print("...logged")
if __name__ == '__main__':
setup_logging()
# Meanwhile, we start a process pool that writes some
# logs. We do this in a loop to make race condition more
# likely to be triggered.
while True:
with Pool() as pool:
pool.apply(runs_in_subprocess)
Trong chương trình trên:
Trong process cha, log messages được điều hướng vào queue, thread đọc từ queue và ghi messages ra file out.log.
Thread khác ghi một stream liên tục ra log messages.
Chúng ta bắt đầu process pool và log một message trong một trong các process con.
Sau khi run:
About to log...
...logged
About to log...
...logged
About to log...
<chương trình sẽ freezes tại điểm này>
Tại sao vậy?
Chúng ta sẽ tìm hiểu những gì xảy ra khi ta bắt đầu 1 process con bằng pool. Mặc định trong Python, khi sử dụng multiprocess thì trình thông dịch sẽ sử dụng phương thức fork(). Đây là cách mà subprocesses được bắt đầu trong Linux hay MacOS.
- Copy process được tạo sử dụng fork() system call.
- Process con thay thế chính nó bằng chương trình khác sử dụng execve() system call.
Xét đoạn code sau:
from os import fork, getpid
print("I am parent process", getpid())
if fork():
print("I am the parent process, with PID", getpid())
else:
print("I am the child process, with PID", getpid())
Kết quả là:
I am parent process 3619
I am the parent process, with PID 3619
I am the child process, with PID 3620
Bạn có thể thấy, không gì ngăn bạn từ việc fork(). Cả process cha và process con đều chạy trong cùng 1 đoạn code.
fork() chỉ là cách Python tạo process pools mặc định bởi Linux, và trên MacOS trên Python 3.7 trở về trước.
Vấn đề với fork()-ing.
Python bắt đầu một pool của các processes bằng việc fork(). Process con đã truy cập để copy mọi thứ từ bộ nhớ của process cha. Nhưng điều gì đã gây nên deadlock ở ví dụ trước đó?
Nguyên nhân của vấn đề trên là tiếp tục chạy code sau khi fork() mà không gọi execve().
- fork() copy mọi thứ trong bộ nhớ, gồm các biến, global configurations,.... Xét ví dụ sau:
import logging
from multiprocessing import Pool
from os import getpid
def runs_in_subprocess():
logging.info(
"I am the child, with PID {}".format(getpid()))
if __name__ == '__main__':
logging.basicConfig(
format='GADZOOKS %(message)s', level=logging.DEBUG)
logging.info(
"I am the parent, with PID {}".format(getpid()))
with Pool() as pool:
pool.apply(runs_in_subprocess)
Sau khi chạy:
GADZOOKS I am the parent, with PID 3884
GADZOOKS I am the child, with PID 3885
Như bạn đã thấy, logging ở process con có cùng format với process cha do đã copy cả config của process cha.
- fork() không copy mọi thứ từ process cha. Xét ví dụ:
from threading import Thread, enumerate
from os import fork
from time import sleep
# Start a thread:
Thread(target=lambda: sleep(60)).start()
if fork():
print("The parent process has {} threads".format(
len(enumerate())))
else:
print("The child process has {} threads".format(
len(enumerate())))
Sau khi run:
The parent process has 2 threads
The child process has 1 threads
Vậy fork() không copy threads của process cha.
Lời giải cho ví dụ 1:
Bất cứ khi nào thread trong process cha ghi log messages, nó được thêm vào Queue. Điều này có nghĩa là nó nắm giữ Lock.
Nếu fork() xảy ra sai thời điểm, lock được copy trong một trạng thái bị giữ.
Process con copy loggin configurations của process cha, bao gồm cả queue.
Bất cứ khi nào process con ghi log message, nó cố ghi ra queue. Điều này có nghĩa là nó cần giữ lock. Nhưng lock đã được acquired trước đó rồi.
Process con bây giờ chờ cho lock đã được acquired ở trên release.
Lock đó sẽ không bao giờ được released, bởi vì thread sẽ release nó không được copy từ process cha sau khi gọi hàm fork().
Cách giải quyết.
reset các configurations của thư viện logging khi các processes con được bắt đầu. Tuy nhiên, với các thư viện khác trong Python mà đòi hỏi một tập các trạng thái global thì không khả thi lắm.
Với các threads trong process cha, chúng cần được released lock khi fork() được gọi. Nhưng cách này cũng không xử lý được vấn đề với các locks được tạo bởi thư viện được viết bằng C. Nó chỉ có thể thực hiện được với các thư viện được viết bằng Python.
Giải pháp đúng đắn.
Thay vì sử dụng fork(), ta có thể dùng spawn như bài của Dr John A Stevenson. Hoặc có thể set như sau:
from multiprocessing import set_start_method
set_start_method("spawn")
Hay:
from multiprocessing import get_context
def your_func():
with get_context("spawn").Pool() as pool:
# ... everything else is unchanged
Thỉnh thoảng, bạn viết code theo các vấn đề mặc định trong documentation sẽ gặp những chuyện rắc rối mà bạn sẽ bối rối đấy.
Chúng ta đã tìm hiểu về threading và multiprocessing để lập trình đa luồng hay đa tiến trình trong Python. Tuy nhiên thư viện mà chúng ta tìm hiểu sau đây có nhiều tiện ích bất ngờ hơn nữa.
concurrent.futures
concurrent.futures là một high level API cho việc lập trình multi-thread hay multi-process.
Executor
Module này có một tính năng là Executor class, là một abstract class và nó không thể sử dụng trực tiếp, nó được kế thừa trong 2 class khác
là ThreadPoolExecutor và ProcessPoolExecutor.
ThreadPoolExecutor
Xét ví dụ:
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def return_after_5_secs(message):
sleep(5)
return message
pool = ThreadPoolExecutor(3)
future = pool.submit(return_after_5_secs, ("hello"))
print(future.done())
sleep(5)
print(future.done())
print(future.result())
Khi submit() một task, ta sẽ nhận lại một Future. Future có một method là done(), nếu future được giải quyết, có 1 giá trị được set cho cho một future object cụ thể. Khi task hoàn thành, thread pool executor đặt giá trị cho future object. Trong ví dụ trên, task sẽ không hoàn thành trong vòng 5 giây, vì vậy lần gọi done() đầu tiên trả về False. Sau khi sleep 5 giây, chúng ta nhận được kết quả của future object bằng việc gọi result() method.
Hiểu về Future object và biết các methods của nó sẽ giúp chúng ta hiểu rõ hơn về code multi-thread trong Python.
ProcessPoolExecutor
Xem ví dụ sau
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def return_after_5_secs(message):
sleep(5)
return message
pool = ProcessPoolExecutor(3)
future = pool.submit(return_after_5_secs, ("hello"))
print(future.done())
sleep(5)
print(future.done())
print("Result: " + future.result())
Chúng ta cần nhớ là ProcessPoolExecutor sử dụng thư viện multiprocessing và do đó không bị tác động bởi GIL. Tuy nhiên ta không thể sử dụng
bất cứ object nào mà not pickable. Nên cần chọn cẩn thận những gì chúng ta sử dụng/trả về trong một callable được truyền vào executor này.
Executor.map()
map method cho phép gọi nhiều lần cho hàm đã cung cấp trong Pool, và truyền mỗi items trong một iterable cho hàm đó. Ngoại trừ trường hợp các hàm được gọi
một cách đồng thời. Với multiprocessing, đối tượng iterable sẽ bị phá vỡ thành các phần và mỗi phần sẽ được truyền vào hàm trong mỗi processes.
Ta có thể điều khiển chunk size bằng cách thêm đối số thứ 3 vào PoolExecutor là chunk_size, mặc định nó là 1.
Ví dụ, thread:
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the url and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
Và process:
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
as_complete() và wait()
concurrent.futures có 2 hàm để làm việc với các đối tượng futures được trả về bởi executor là as_complete() và wait().
as_complete() nhận một iterable của Future object và bắt đầu yeilding các giá trị ngay khi futures bắt đầu chạy. Nó khác với map() ở chỗ map() trả về các kết quả theo thứ tự iterables được truyền vào. Nên kết quả đầu tiên của map() là kết quả cho phần tử đầu tiên. Trong khi với as_complete(), giá trị trả về đầu tiên phụ thuộc vào cái nào hoàn thành trước. Ví dụ:
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
from time import sleep
from random import randint
def return_after_5_secs(num):
sleep(randint(1, 5))
return "Return of {}".format(num)
pool = ThreadPoolExecutor(5)
futures = []
for x in range(5):
futures.append(pool.submit(return_after_5_secs, x))
for x in as_completed(futures):
print(x.result())
wait() sẽ trả về một named tuple, chứa 2 set, một set chứa các futures đã hoàn thành (kể cả có kết quả hay là một exception) và set kia chứa các futures chưa complete. Ví dụ:
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
from time import sleep
from random import randint
def return_after_5_secs(num):
sleep(randint(1, 5))
return "Return of {}".format(num)
pool = ThreadPoolExecutor(5)
futures = []
for x in range(5):
futures.append(pool.submit(return_after_5_secs, x))
print(wait(futures))
Sau khi chạy sẽ được 1 named tuple như sau: DoneAndNotDoneFutures(done={...},not_done=set())
Kết
Chủ đề về threads và processes trong Python khá là hấp dẫn với mình, tuy nhiên còn nhiều vấn đề thực tế khác mà khi bắt tay vào code chúng ta mới gặp được. Mong là những phần mình đã trình bày sẽ giúp được bạn ít nhiều.
Nguồn
- RealPython, keyword: threading.
- Medium
- Pythonspeed
- Abu Ashraf Masnun blog