
# Threads, Processes Trong Python (Phần 1)
Khi nhắc tới Python, hẳn chúng ta đã phải biết GIL có tầm quan trọng ra sao đối với ngôn ngữ này. Từ việc sử dụng GIL, các khái niệm về threads, processes cũng có chút đặc biệt mà chúng ta cần lưu tâm khi làm việc với Python. Bài này mình sẽ giới thiệu các khái niệm:
- Thread trong Python và các thư viện của nó (
threading). - Process trong Python và thư viện (
multiprocessing). - Thư viện
concurrent.futures.
Thread
Ở bài trước chúng ta đã tìm hiểu kỹ cơ chế hoạt động của GIL, và cũng làm quen qua khái niệm thread.
Thread là một luồng thực thi của chương trình, giả sử chương trình của bạn có 2 hàm thì với thread, chương trình của bạn có thể làm 2 việc cùng một lúc thay vì làm từng việc theo thứ tự hàm được gọi.
Cũng bởi GIL nên việc sử dụng đa luồng (multithreading) không đem lại hiệu quả bao nhiêu vì GIL chỉ cho phép 1 luồng được thực thi tại 1 thời điểm. Điều này giúp ta quản lý tài nguyên 1 cách đơn giản nhất, tránh được các vấn đề như race condition và deadlocks. Nhưng cũng không có nghĩa là đa luồng không có tí tác dụng gì trong Python. Với các chương trình đòi hỏi nhiều tác vụ liên quan tới I/O như request tài nguyên từ internet, đọc/ghi file,... ở nơi mà các task sẽ mất nhiều thời gian để đợi response từ các nguồn trên thì multithreading lại mang lại hiệu năng đáng kể so với chạy tuần tự hay đa tiến trình (multiprocessing).
Bắt đầu với Threading.
1. Single thread.
Xét đoạn code sau (viết trong 1 file có tên test_single_thread.py):
import threading
import logging
import time
def thread_func(name):
logging.info('Thread %s: starting', name)
time.sleep(3)
logging.info('Thread %s: finishing', name)
if __name__ == '__main__':
format = '%(asctime)s: %(message)s'
logging.basicConfig(format=format, level=logging.INFO, datefmt='%H:%M:%S')
logging.info('Main : before creating thread')
x = threading.Thread(target=thread_func, args=(1,))
logging.info('Main : wait for the thread to finish')
# x.join()
logging.info('Main : all done')
Ở đoạn code trên, chúng ta sử dụng thư viện threading để tạo 1 thread cho hàm thread_func, đối số truyền vào là 1 nên biến name đã định nghĩa ở trên sẽ nhận giá trị 1.
Khi chạy chương trình, ta sẽ thấy kết quả sau:
python test_single_thread.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
Thread 1: finishing
Bạn chú ý chỗ Main kết thúc trước khi Thread 1 kết thúc. Nếu bạn uncomment dòng x.join() ở đoạn code trên thì sẽ có khác biệt đấy.
daemon threads
Trong KHMT, khái niệm daemon để chỉ những tiến trình chạy ở background. Với Python thì có một nghĩa đặc biệt khác cho từ daemon. Một daemon thread sẽ shutdown lập tức khi chương trình exit. Hay hiểu cách khác là daemon thread là các thread chạy ở background mà bạn không cần phải lo lắng về việc shutdown nó. Nếu một chương trình chạy các threads mà không phải daemon, nó sẽ phải chờ các threads này thực thi xong trước khi kết thúc.
Trở lại với đoạn code ví dụ ở trên, khi chương trình chạy, nó sẽ được báo là có 1 sự tạm ngưng 3s sau khi __main__ in ra all done mà trước khi thread hoàn thành. Sự tạm ngưng là Python đang chờ những non-daemonic thread hoàn tất. Khi chương trình kết thúc, một phần của tiến trình shutdown là dọn dẹp quy trình phân luồng.
Nếu soi vào source code của Python threading, bạn sẽ thấy hàm threading._shutdown()
đi xuyên qua tất cả các luồng đang chạy và gọi .join() trên mỗi luồng mà không có daemon flag được set.
Vì vậy, chương trình chờ để thoát bởi vì thread đang chờ trong trạng thái sleep. Ngay khi nó hoàn thành, .join() sẽ trả về kết quả và thoát ra khỏi chương trình.
Nếu ta copy đoạn code trên vào file test_daemon.py và sửa lại x như sau:
x = threading.Thread(target=thread_func, args=(1,), daemon=True)
và chạy lại, kết quả sẽ là:
./test_daemon.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
So với ví dụ 1, đoạn code này cho ra kết quả khác ở chỗ hàm thread_func không có cơ hội hoàn tất, vì nó là daemon thread, vì vậy khi __main__ vươn tới dòng code cuối,
chương trình muốn kết thúc và daemon bị killed.
join() một thread
Các daemon threads rất hữu ích, nhưng giả sử bạn muốn chờ thread đang ngừng và không thoát khỏi chương trình khi chưa thực hiện xong thread thì sao?
Với ví dụ 1, bạn sẽ thấy dòng bị comment là # x.join(). Nếu bạn uncomment nó thì chương trình sẽ chờ thread hoàn tất rồi mới thoát.
2. Multi threads.
Xét ví dụ sau (file test_multi_thread.py):
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
threads = list()
for index in range(3):
logging.info("Main : create and start thread %d.", index)
x = threading.Thread(target=thread_function, args=(index,))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
logging.info("Main : before joining thread %d.", index)
thread.join()
logging.info("Main : thread %d done", index)
Khi chạy chương trình trên:
./multiple_threads.py
Main : create and start thread 0.
Thread 0: starting
Main : create and start thread 1.
Thread 1: starting
Main : create and start thread 2.
Thread 2: starting
Main : before joining thread 0.
Thread 2: finishing
Thread 1: finishing
Thread 0: finishing
Main : thread 0 done
Main : before joining thread 1.
Main : thread 1 done
Main : before joining thread 2.
Main : thread 2 done
Nhìn kỹ thông tin output, bạn sẽ thấy 3 threads start với trật tự như logic chương trình (từ 0-2). Nhưng khi threads kết thúc, trật tự của nó được thể hiện theo chiều ngược lại (từ 2-0).
Trật tự mà thread nào được chạy và kết thúc sẽ được xác định bởi HĐH và khá là khó để dự đoán, nói cách khác, nó tương đối ngẫu nhiên. Bạn cần phải cẩn thận khi thiết kết các algorithms để làm việc với các threads.
Để điều phối trật tự các threads, bạn có thể tìm hiểu concurrent.futures
Các vấn đề thường gặp với muti threading
Race conditions.
Race conditions có thể xảy ra khi 2 hay nhiều threads truy cập vào một phần data hoặc tài nguyên được shared. Xét ví dụ sau:
import concurent.futures
import logging
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
Chương trình trên tạo ra một ThreadPoolExecutor với 2 threads, sau đó gọi method .submit() trên từng thread, bảo chúng chạy method database.update().
dạng được defined của .submit(): .submit(function, *args, **kwargs).
Khi chương trình trên chạy, mỗi threads chạy .update() và nó cộng 1 vào .value, chúng ta đang mong đợi database.value sau khi kết thúc chương trình là 2 nhưng hãy xem kết quả:
./test_race_conditions.py
Testing unlocked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing unlocked update. Ending value is 1.
giá trị sau khi kết thúc chương trình là 1. Ta sẽ cùng tìm hiểu chi tiết nhé!
Đầu tiên ta phải hiểu threads hoạt động như nào đã
Khi bạn ra lệnh cho ThreadPoolExecutor chạy mỗi thread, bạn chỉ định cho nó hàm nào cần chạy, tham số nào cần truyền vào. (executor.submit(database.update, index)) Kết quả là mỗi threads trong pool sẽ gọi database.update(index) (database là một reference tới một đối tượng FakeDatabase được tạo trong __main__, gọi .update() trên object đó tương ứng với gọi một instance method trên đối tượng đó).
Mỗi thread có một reference tới đối tượng FakeDatabase y chang nhau là database. Mỗi thread sẽ cũng có một giá trị duy nhất là index.
Ta sẽ demo race conditions bằng ví dụ sau:
Xét trường hợp chương trình chỉ có một thread chạy:
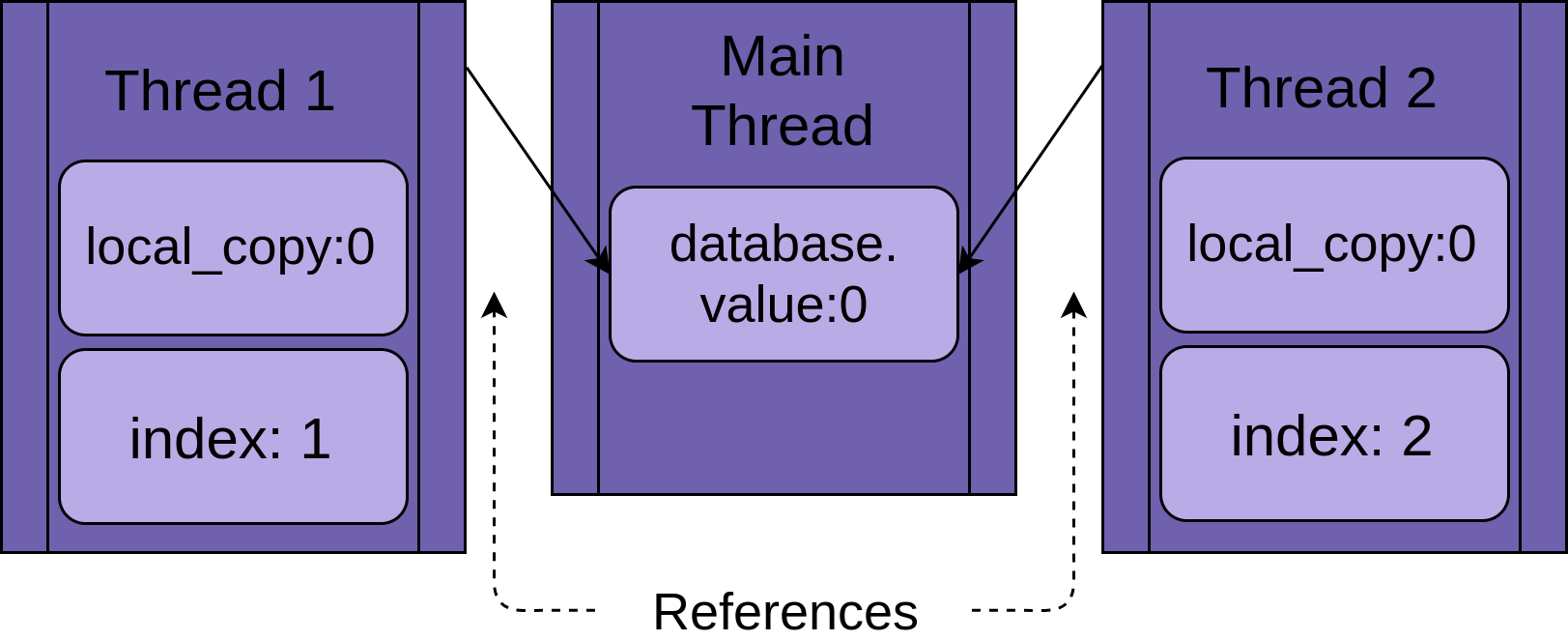
Khi thread bắt đầu chạy method .update(), nó có một version của tất cả data local của riêng nó. Trong trường hợp này là biến local_copy.
Điều này thật sự tốt.
Trường hợp khác, 2 thread chạy cùng 1 hàm sẽ luôn luôn confuse với mỗi thread. Điều này có nghĩa là tất cả các biến trong scope của hàm là thread-safe.
Hình sau sẽ mô tả từng bước thực thi của chương trình nếu chỉ có 1 thread chạy.
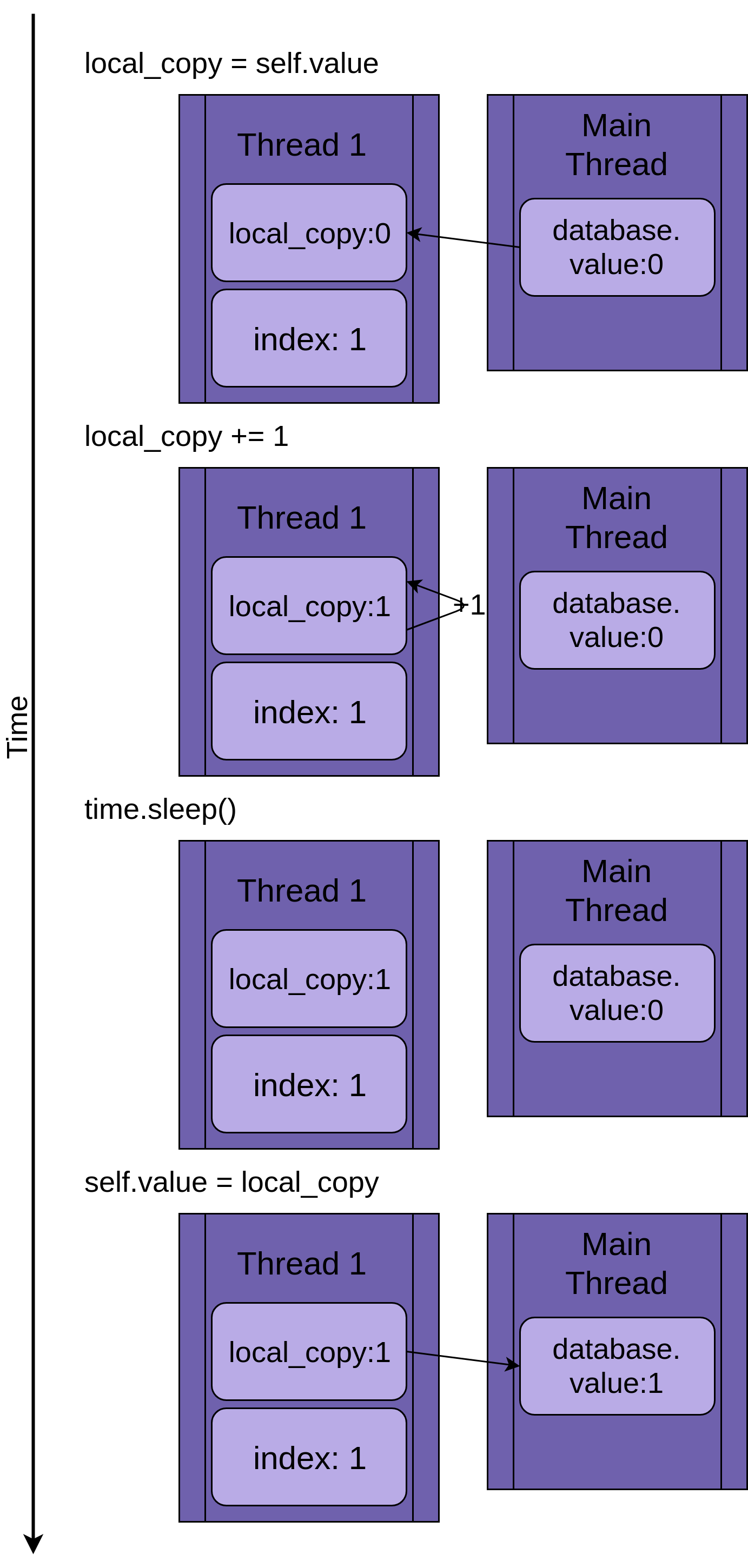
Khi thread 1 bắt đầu, FakeDatabase.value là 0. Dòng đầu tiên trong method .update() là local_copy = self.value, copies giá trị 0 vào biến local.
Kế tiếp, giá trị của local_copy tăng lên 1 đơn vị. Bạn có thể thấy giá trị .value trong thread 1 là 1.
Tiếp theo, time.sleep() được gọi, nó làm cho thread hiện tại pause và cho phép các threads khác chạy.
Khi thread 1 wakes up và tiếp tục, nó copies giá trị mới từ biến local_copy vào FakeDatabase.value, và hoàn thành thread 1, bạn có thể thấy database.value là 1.
Xét trường hợp chương trình có 2 thread chạy:
Thread 1 bắt đầu chạy:
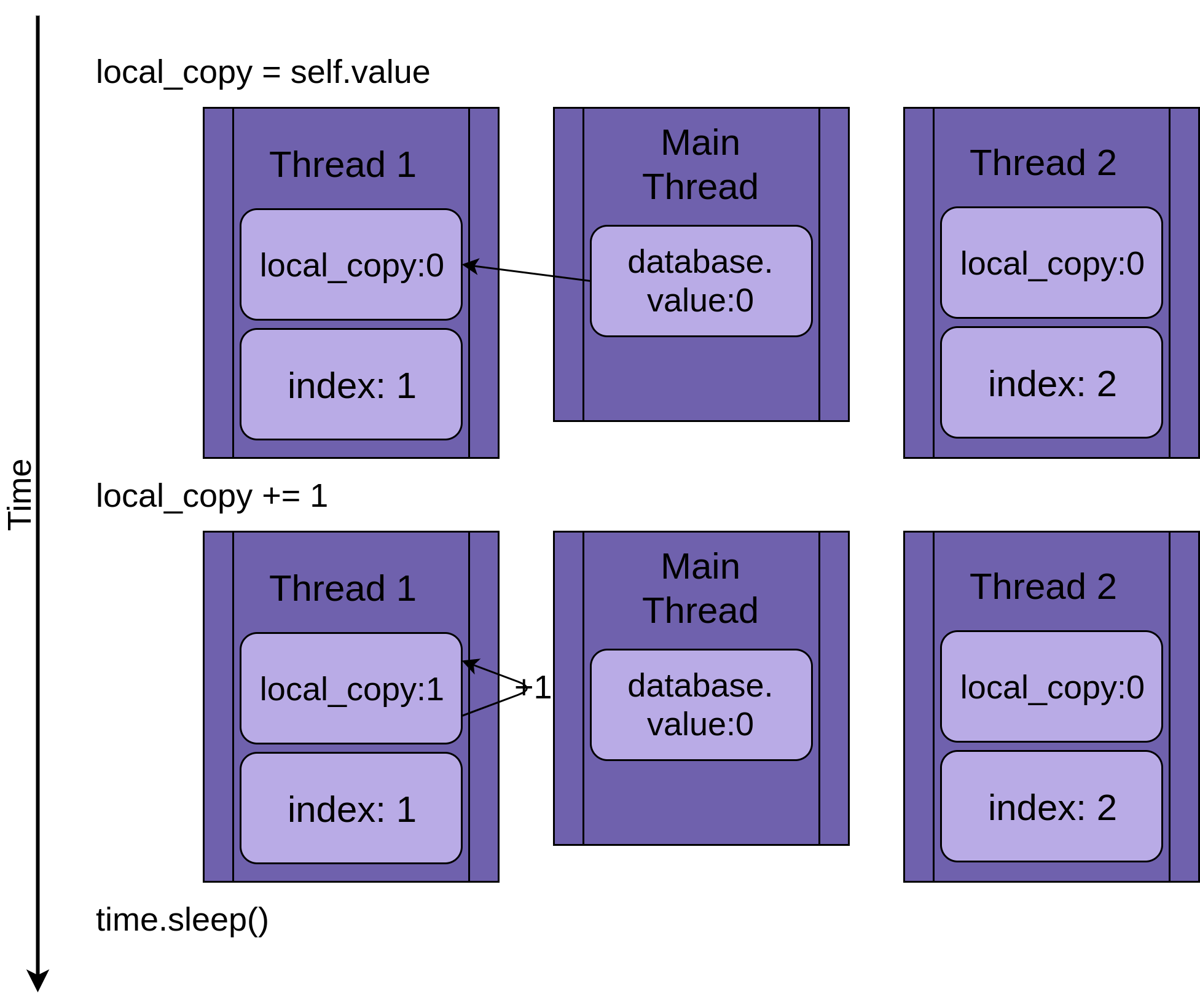
Khi thread 1 chạy tới đoạn time.sleep(). Nó cho phép các threads khác bắt đầu chạy. Thread 2 bắt đầu chạy và thực hiện các phép toán giống thread 1. Như hình sau:
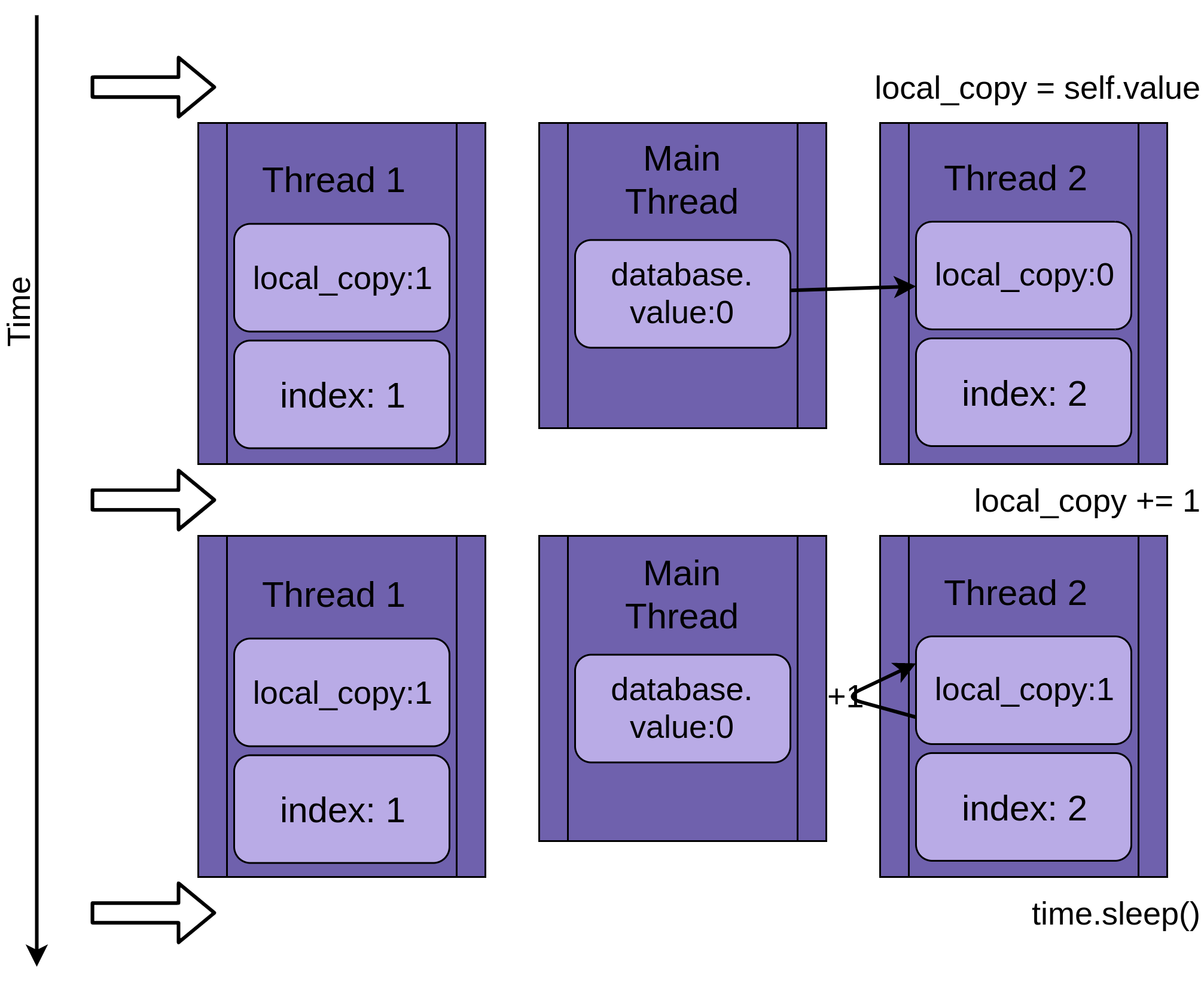
Khi thread 2 sleep, giá trị được shared giữa 2 thread là database.value vẫn không đổi là 0 và 2 versions riêng của biến local_copy 2 thread đều có giá trị 1.
Tới đây, thread 1 wakes up và lưu giá trị của local_copy sau đó kết thúc, tới phiên thread 2 chạy, Thread 2 cũng update database.value với giá trị của local_copy của riêng mình. Kết quả là 1:
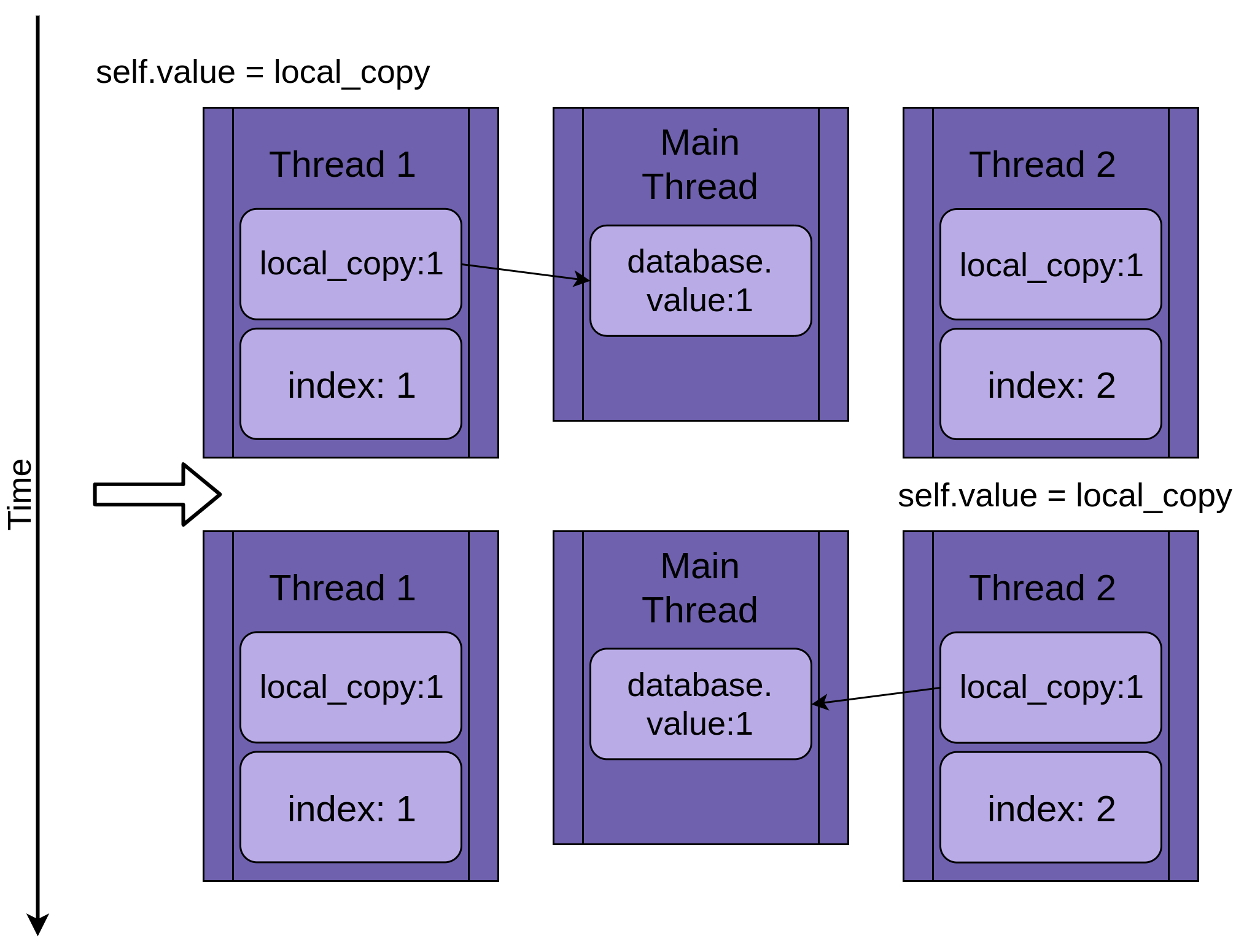
2 Theads truy cập xen kẽ vào 1 share object đơn, ghi đè mỗi kết quả của riêng mình lên share object đó. Tương tự race conditions có thể phát sinh khi một thread frees bộ nhớ dùng chung hay closes file handle trước khi thread khác hoàn tất công việc của mình.
Đồng bộ hóa cơ bản sử dụng Lock (Basic synchronization using Lock)
Một trong các cách để chống lại race conditions là dùng Lock.
Để giải quyết race conditions ở ví dụ bên trên, bạn cần tìm cách để cho phép chỉ 1 thread tại 1 thời điểm đọc-thay đổi-ghi tài nguyên. Cách đó là dùng Lock. Trong Python, nó được gọi là Lock, với các ngôn ngữ khác có một khái niệm tương tự là mutex, cũng có chức năng như Lock.
Chỉ 1 thread được giữ Lock object tại 1 thời điểm, bất cứ threads nào khác muốn Lock object để thực thi thì phải đợi cho tới khi chủ sở hữu của Lock đó bỏ nó ra.
Hàm .acquire() và .release() được dùng để nắm và giải phóng Lock. Khi 1 thread muốn nắm Lock, nó sẽ gọi phương thức .acquire(), nếu Lock đang được
giữ bởi thread khác, nó sẽ đợi tới khi thread đó giải phóng Lock. Bạn cần chú ý chỗ này, nếu 1 thread giữ Lock nhưng không làm gì cả và cũng không giải phóng
thì nó sẽ làm chương trình bị đứng, ở bài trước mình đã giới thiệu cơ chế ticks của Python interpreter. Bạn có thể tham khảo lại
Khá là may mắn là Python Lock cũng vận hành như 1 context manager, vì vậy bạn có thể dùng nó với câu lệnh with. Và nó sẽ được giải phóng tự động
khi thoát ra khỏi with block. Xét ví dụ:
import threading
import logging
import concurrent.futures
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock:
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.DEBUG,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
Bạn có thể thấy, khi chương trình chạy, 1 thead sẽ giữ Lock cho đến khi hoàn thành việc update data tới shared object. Bạn sẽ được kết quả như mong muốn:
./fix_race_conditions.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 0 about to lock
Thread 0 has lock
Thread 1: starting update
Thread 1 about to lock
Thread 0 about to release lock
Thread 0 after release
Thread 0: finishing update
Thread 1 has lock
Thread 1 about to release lock
Thread 1 after release
Thread 1: finishing update
Testing locked update. Ending value is 2.
Tới đây, chúng ta sẽ xét 1 trường hợp đặc biệt nữa khi dùng Lock, nếu 1 thread gọi .acquire() 2 lần, lần 1 nó đã giữ Lock rồi nhưng vẫn gọi .acquire() lần nữa Kết quả là nó sẽ đứng chờ chính nó nhả Lock ra, gây ra một lỗi khác là Deadlock.
Deadlock.
Xét ví dụ sau:
import threading
l = threading.Lock()
print("before first acquire")
l.acquire()
print("before second acquire")
l.acquire()
print("acquired lock twice")
Khi bạn release() không đúng cách nó cũng gây ra deadlock, điều này có thể khắc phục bằng các dùng context manager.
Hoặc là khi vấn đề thiết kế mà 1 hàm tiện ích cần được gọi bởi các hàm khác mà chúng có thể hoặc không thể có Lock. Python cũng khắc phục điều này luôn cho chúng ta, có một đối tượng khác gọi là RLock. Nó cho phép một thread acquire một RLock nhiều lần trước khi nó gọi .release(). Bạn có thể tìm hiểu kỹ hơn tại đây
Nhìn chung, Lock và RLock là 2 tools cơ bản được sử dụng trong lập trình đa luồng để chống lại race conditions. Nhưng vẫn có những giải pháp khác mà mình sẽ giới thiệu sau đây.
Producer-Comsumer threading.
Vấn đề Producer-Consumer là một chuẩn trong computer science thường được xem như vấn đề đồng bộ hóa threading hay process.
Giả sử bạn có một chương trình đọc tin nhắn từ internet sau đó ghi tin nhắn đó vào ổ cứng. Chương trình này lắng nghe và chấp nhận tin nhắn khi chúng được gửi tới. Chúng không đến một các đều đặn, có thể đến một cách liên tục. Phần chương trình này tạm gọi là producer.
Mặc khác, khi bạn có một tin nhắn, bạn ghi nó vào database. Database access thì chậm nhưng vẫn đủ nhanh để theo kịp nhịp độ trung bình của tin nhắn được gửi tới. Nhưng lại không đủ nhanh để bắt kịp các tin nhắn được gửi tới liên tục. Phần này ta tạm gọi là consumer.
Giữa producer và consumer, ta sẽ tạo 1 pipeline nó sẽ là một phần thay đổi khi bạn tìm hiểu về đồng bộ hóa giữa các đối tượng khác nhau.
Producer-Consumer sử dụng Lock.
Xét ví dụ sau:
import random
import threading
import concurrent.futures
import logging
SENTINEL = object()
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:about to acquire getlock", name)
self.consumer_lock.acquire()
logging.debug("%s:have getlock", name)
message = self.message
logging.debug("%s:about to release setlock", name)
self.producer_lock.release()
logging.debug("%s:setlock released", name)
return message
def set_message(self, message, name):
logging.debug("%s:about to acquire setlock", name)
self.producer_lock.acquire()
logging.debug("%s:have setlock", name)
self.message = message
logging.debug("%s:about to release getlock", name)
self.consumer_lock.release()
logging.debug("%s:getlock released", name)
def producer(pipeline):
"""Pretend we're getting a message from the network."""
for index in range(10):
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
# Send a sentinel message to tell consumer we're done
pipeline.set_message(SENTINEL, "Producer")
def consumer(pipeline):
"""Pretend we're saving a number in the database."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer storing message: %s", message)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
Đoạn code trên demo producer sử dụng fake message, chúng ta dùng thư viện random cho việc đó. producer cũng sử dụng SENTINEL để ra tín hiệu
cho consumer ngưng sau khi nó đã gửi xong 10 giá trị.
consumer đọc messages từ pipeline và ghi ra màn hình. Nếu nó lấy giá trị SENTINEL, nó trả về giá trị và kết thúc thread.
Nhìn vào đoạn __main__, chúng ta sẽ spawn 2 thread.
Trong class Pipeline:
__init__() khởi tạo giá trị của message, producer_lock và consumer_lock, sau đó gọi .acquire() trên consumer_lock. Đây là trạng thái chúng ta muốn bắt đầu producer được phép thêm một message mới, nhưng consumer cần đợi tới khi message được gửi đến.
get_message() và set_message() gần như là 2 công việc đối lập. get_message() gọi .acquire() trên consumer_lock. Điều này sẽ làm cho consumer chờ cho tới khi message sẵn sàng.
Một khi consumer đã có được consumer_lock, nó copy giá trị trong message sau đó gọi .release() trên producer_lock. Giải phóng lock này cho phép producer chèn message kế tiếp vào pipeline.
Ngay khi consumer gọi .producer_lock.release(), nó có thể được đổi chỗ. producer có thể bắt đầu chạy tiếp. Nó có thể xảy ra trước khi .release() trả về. Điều này có nghĩa là có một khả năng nhỏ khi hàm trả về self.messages, nó thực ra có thể là message kế tiếp được sinh ra. Vì vậy bạn sẽ mất message đầu tiên.
Tới method .set_mesage(), bạn có thể thấy việc giao dịch theo chiều ngược lại. producer gọi với một message. Nó sẽ thu .producer_lock, set giá trị của .message và gọi .release() sau đó trên consumer_lock.
Chạy code trên sẽ được kết quả:
./prodcom_lock.py
Producer got data 43
Producer got data 45
Consumer storing data: 43
Producer got data 86
Consumer storing data: 45
Producer got data 40
Consumer storing data: 86
Producer got data 62
Consumer storing data: 40
Producer got data 15
Consumer storing data: 62
Producer got data 16
Consumer storing data: 15
Producer got data 61
Consumer storing data: 16
Producer got data 73
Consumer storing data: 61
Producer got data 22
Consumer storing data: 73
Consumer storing data: 22
Ở cách này, nó chỉ cho phép một giá trị đơn trong pipeline tại một thời điểm, khi producer nhận 1 loạt các messages, nó sẽ không biết phải đặt các messages này ở đâu. Nên đây không phải là một giải pháp tốt trong vấn đề producer-consumer.
Ta sẽ tìm hiểu cách tiếp theo.
Producer-Consumer sử dụng Queue.
Nếu bạn muốn xử lý nhiều hơn 1 giá trị trong pipeline tại 1 thời điểm, bạn sẽ cần một cấu trúc dữ liệu cho pipeline đó cho phép một số to ra và co lại như dữ liệu back up từ producer.
Python có module queue rất phù hợp cho việc này, ta hãy cùng áp dụng xem sao nhé!
Ở cách này chúng ta cũng sẽ dùng cách khác để dừng các worker threads bằng việc sử dụng threading.Event.
threading.Event cho phép một thread ra hiệu một event trong khi các thread khác có thể chờ cho event đó xảy ra. Chìa khóa sử dụng trong
trường hợp này là các threads đang chờ event không cần phải ngừng những gì chúng đang làm, chúng có thể check trạng thái của Event mỗi lúc một lần.
import random
import threading
import queue
import logging
import concurrent.futures
import time
def producer(pipeline, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
logging.info("Producer received EXIT event. Exiting")
def consumer(pipeline, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not pipeline.empty():
message = pipeline.get_message("Consumer")
logging.info(
"Consumer storing message: %s (queue size=%s)",
message,
pipeline.qsize(),
)
logging.info("Consumer received EXIT event. Exiting")
class Pipeline(queue.Queue):
def __init__(self):
super().__init__(maxsize=10)
def get_message(self, name):
logging.debug("%s:about to get from queue", name)
value = self.get()
logging.debug("%s:got %d from queue", name, value)
return value
def set_message(self, value, name):
logging.debug("%s:about to add %d to queue", name, value)
self.put(value)
logging.debug("%s:added %d to queue", name, value)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
Trong ví dụ này, main thread sẽ đơn giản chỉ là sleep 1 lúc, sau đó là .set() nó.
Chúng ta cũng không cần dùng biến SENTINEL trong pipeline. Bù lại, code sẽ phức tạp hơn một chút. Không chỉ lặp tới khi event được set, mà còn tiếp tục lặp tới khi pipeline được emptied.
Cần đảm bảo rằng queue rỗng trước khi consumer hoàn thành. Nếu consumer không tồn tại trong khi pipeline có messages, sẽ có 2 điều tồi tệ sẽ xảy ra: Một là bạn sẽ mất message cuối cùng, hai là producer có thể bị bắt khi cố gắng thêm message vào queue đầy và không bao giờ return. Điều này xảy ra khi events được triggered sau khi producer check điều kiện .is_set() nhưng trước khi gọi pipeline.set_message().
Nếu nó xảy ra, producer có khả năng sẽ wakes up và thoát với queue vẫn đầy. producer sẽ gọi .set_message() sau đó sẽ chờ tới khi có một không gian trên queue cho message mới.
Trong Pipeline, maxsize là giới hạn số phần tử của queue. Gây ra .put() chặn cho tới khi các phần tử trong queue ít hơn maxsize. Nếu không set giá trị cho maxsize, queue sẽ dần chiếm hết bộ nhớ của máy bạn, nên chú ý ở đây nhé!
.get_message() và set_message() cơ bản là wrap .get() và .put() trên Queue.
Queue là thread-safe.
Khi chạy đoạn code trên, ta sẽ có kết quả sau:
./prodcom_queue.py
Producer got message: 32
Producer got message: 51
Producer got message: 25
Producer got message: 94
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Producer got message: 31
.........
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Main: about to set event
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
Có thể thấy cách này tốt hơn đối với vấn đề producer-consumer.
Ta đã tìm hiểu qua việc giải quyết race conditions bằng việc dùng Lock và Queue, tuy nhiên vẫn còn những phương pháp khác, mình sẽ trình bày ngay sau đây.
Threading objects.
Semaphore.
Trong module threading của Python có một object gọi là Semaphore. Một semaphore trong Python là một bộ đếm với một số ít các thuộc tính đặc biệt.
Đầu tiên, semaphore là atomic. Có nghĩa là nó được đảm bảo rằng hệ điều hành sẽ không hoán đổi thread trong giai đoạn đang tăng hoặc giảm counter. bộ đếm nội bộ sẽ tăng khi bạn gọi .release() và giảm khi bạn gọi .acquire().
Tiếp theo, nếu một thread gọi .acquire() why counter là 0, thread đó sẽ bị block cho tới khi thread khác gọi .release() và tăng counter tới 1.
Semaphore được dùng để bảo vệ tài nguyên với dung lượng giới hạn. Ví dụ bạn có một bể các connections và muốn giới hạn cái bể đó bằng 1 số xác định.
Timer.
threading.Timer là một cách để schedule một hàm được gọi sau một khoảng thời gian cố định được truyền vào. Ví dụ:
import threading
t = threading.Timer(30.0, my_function)
Bạn bắt đầu Timer bằng việc gọi *.start(). Hàm sẽ được gọi trong một thread tại vài thời điểm sau mỗi thời gian xác định, nhưng nên cẩn thận không có gì đảm bảo rằng nó sẽ được gọi một cách chính xác tại thời điểm bạn muốn đâu.
Nếu bạn muốn ngừng một Timer đã bắt đầu rồi, bạn có thể hủy nó bằng cách gọi .cancel().
Một Timer có thể được sử dụng để nhắc nhở user một hành động sau mỗi thời gian xác định. Nếu user thực hiện hành động đó trước khi Timer hết hạn, .cancel() sẽ được gọi.
Barrier
Một threading.Barrier có thể được sử dụng để giữ một số cố định của các threads trong việc đồng bộ hóa. Khi tạo một Barrier, caller phải xác định bao nhiêu threads sẽ cần đồng bộ. Mỗi thread gọi .wait() trên Barrier.
Chúng sẽ duy trì việc bị chặn tới khi một số xác định của các threads đang chờ. Sau đó chúng sẽ được giải phóng tại cùng 1 thời điểm.
Nhớ rằng các threads được schedule bởi HĐH nên mặc dù các threads được giải phóng một cách đồng thời, chúng sẽ được scheduleed để chạy một lần tại một thời điểm.
Một công dụng của Barrier là cho phép một bể các threads khởi tạo. Có các threads chờ trong Barrier sau khi chúng được khởi tạo sẽ đảm bảo rằng không thread nào được chạy trước khi tất cả các threads đó hoàn thành việc khởi tạo.
Hết phần 1, chúng ta hãy sang phần tiếp theo của chủ đề này...