
# Concurrency và Parallelism trong Python
Ở chủ đề về threads và processes chúng ta đã biết về threads, processes lfà gì và các thư viện multithreading, multiprocessing cũng như concurrent.futures Trong bài này, mình sẽ giới thiệu:
- Concurrency là gì và ứng dụng ra sao với
theading,concurrent.futuresvàasyncio. - Parallelism là gì và ứng dụng với
multiprocessing.
Concurrency
Concurrency nghĩa là khi bạn thực thi các công việc một cách đồng thời. Trong Python, những thứ xảy ra đồng thời được gọi bởi các tên khác nhau như threads, processes, tasks. Nhưng ở mức high level, chúng refer tới một dãy các lệnh chạy theo thứ tự.
Mỗi loại concurrency trên đều có thể bị ngừng tại các điểm quan trọng, và CPU đang xử lý chúng có thể chuyển đổi giữa các context. Trạng thái của mỗi context được lưu lại, vì thế chúng có thể được khởi động lại ngay nơi chúng bị interrupted.
Bạn sẽ thắc mắc rằng tại sao Python sử dụng các từ khác nhau cho cùng 1 khái niệm? Vì threads, processes hay tasks đều như nhau nếu chúng ta nhìn nó ở mức high level. Nhưng khi đi vào chi tiết, mỗi loại sẽ có những đặc tính khác nhau.
Bạn cần phải cẩn thận vì khi đi vào chi tiết, chỉ multiprocessing là thực sự chạy các tác vụ tại 1 thời điểm. Các thư viện làm việc với threads như threading hay asyncio đều chạy trên 1 nhân xử lý, chúng chỉ tìm một cách khéo léo để thay phiên nhau nhằm tăng tốc toàn bộ tiến trình.
Cách mà các threads, tasks luân phiên nhau cũng khác nhau giữa các thư viện threading và asyncio. Trong threading, HĐH thực sự biết mỗi thread đang có những gì và có thể interrupt (ngắt) nó tại bất kỳ thời điểm nào mà bắt đầu chạy một thread khác. Đây gọi là "pre-emptive multitasking", tạm dịch là là đa nhiệm ưu tiên (thực sự trong CS tiếng anh dịch ra tiếng việt nó tối nghĩa kiểu gì ấy). Nó sử dụng một cơ chế ngắt (interrupt mechanism) là hoãn lại task đang xử lý và gọi lên scheduler để xác định xem task nào sẽ được thực thi tiếp theo. HĐH chịu trách nhiệm khởi tạo một context switch thỏa mãn một ràng buộc của chính sách scheduling ưu tiên. Kèm theo đó là pre-emptive multitasking chạy trong một protection ring, nên trong quá trình interrupting và resuming dữ liệu của task được bảo vệ.
Pre-emtive multitasking hữu dụng trong trường hợp code trong tasks không cần làm gì cả để switch. Nó cũng sẽ trở nên khó nhằn bởi vì từ "bất cứ khi nào", sự chuyển đổi này có thể xảy ra ngay cả khi task đó đang thực thi 1 câu lệnh Python. Sự switch giữa các tasks với nhau được quyết định bởi HĐH
Asyncio thì khác, nó được gọi là "cooperative multitasking". Ở đây, HĐH không khởi tạo context switch, thay vào đó các tasks tình nguyện trả về sự điều khiển một cách định kỳ, khi nào nghỉ chạy, khi nào bị chặn một cách logic. Các task phải hợp tác với nhau bằng việc thông báo khi nào chúng sẵn sàng để được switch. Điều đó có nghĩa là code trong task phải thay đổi 1 chút để nó có thể xảy ra. Lúc này, chức năng scheduler của HĐH sẽ có vai trò giới hạn để bắt đầu một task và để task trả về control một cách tự nguyện.
Lợi ích của việc làm việc này là bạn sẽ luôn biết nhiệm vụ của mình sẽ được hoán đổi ở đâu. Nó sẽ không chuyển đổi trong khi đang ở giữa một câu lệnh Python trừ khi câu lệnh đó được đánh dấu.
Parallelism
Nếu máy tính của bạn có nhiều hơn 1 lõi CPU, bạn nên tìm hiểu về multiprocessing nếu code với Python.
Trong multiprocessing, Python tạo mới các processes. Một process ở đây có thể được hiểu là một chương trình hoàn toàn khác, mặc dù về mặc kỹ thuật chúng thường được định nghĩa như một tập các tài nguyên, tài nguyên ở đây là bộ nhớ, file handles,... Cũng có thể hiểu mỗi process chạy trên một Python interpreter của riêng nó.
Vì chạy trên nhiều lõi CPU nên chúng hoàn toàn có thể chạy đồng thời với nhau. Việc này có vẻ phức tạp, nhưng Python đã làm rất tốt trong việc khiến parallelism trở nên trơn tru hơn bao giờ hết.
I/O bound và CPU bound.
I/O-bound gây ra việc chương trình sẽ bị chậm lại vì phải thường xuyên dừng lại để chờ phản hồi từ các tác vụ I/O. Chúng xảy ra thường xuyên khi chương trình hay làm việc với những thứ chậm hơn CPU, như đọc/ghi files, request tài nguyên trên Internet,...
Xem hình dưới đây:
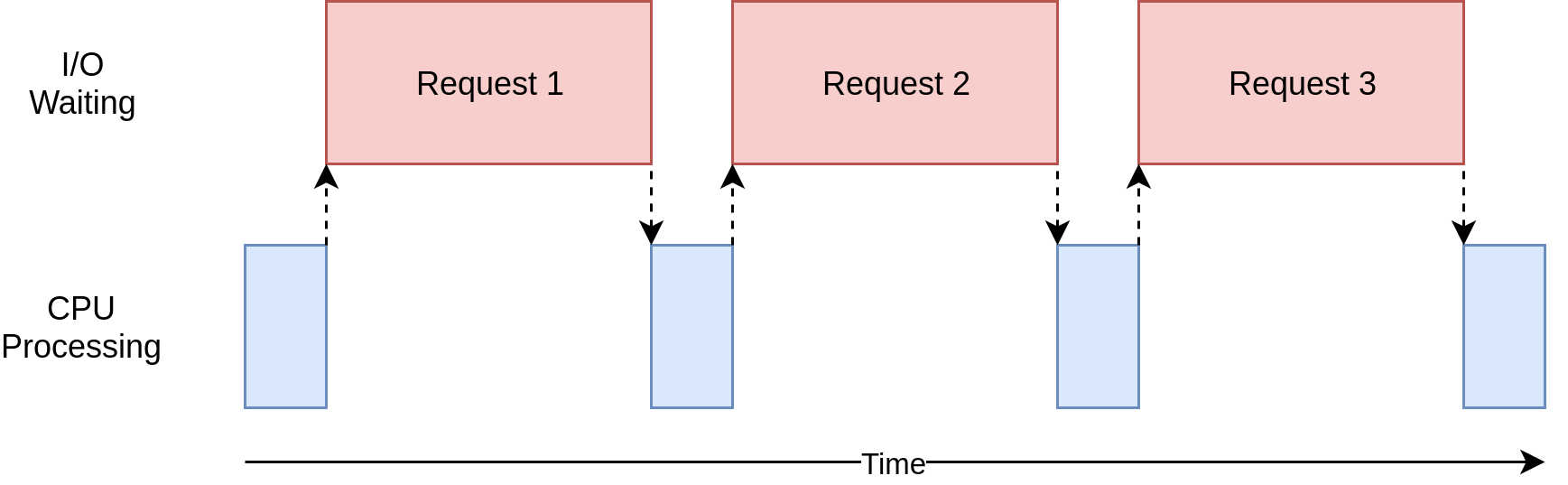
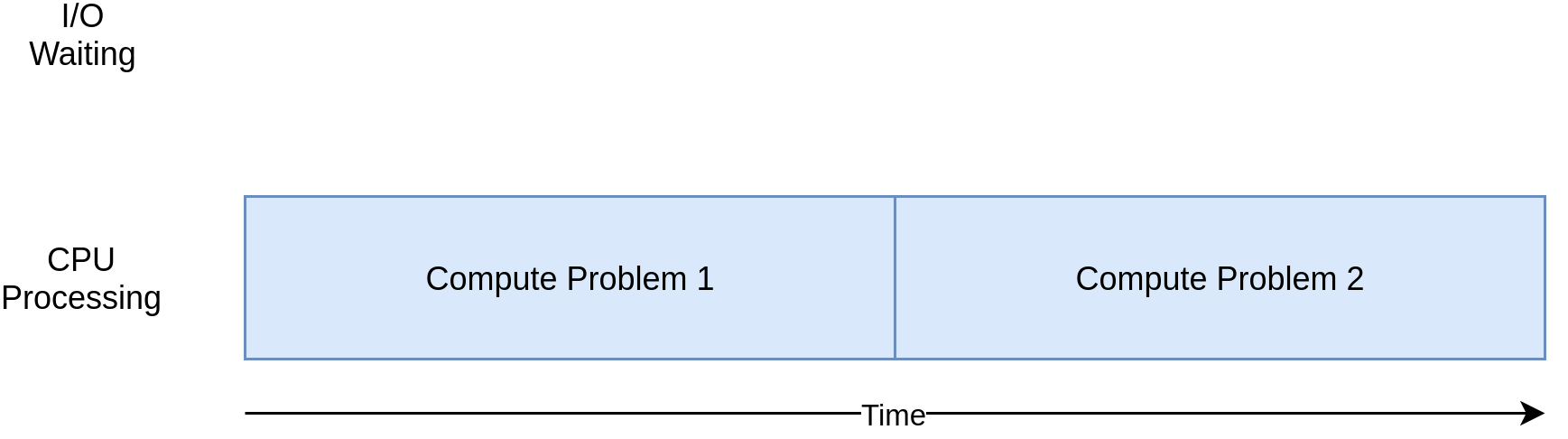
CPU-bound ngược với I/O bound, tức là những tác vụ chỉ yêu cầu khả năng tính toán nặng, không phải chờ phản hồi từ I/O. Tác nhân duy nhất giới hạn tốc độ của chương trình là CPU. Xem hình sau đây:
Chúng ta sẽ tổng hợp một cách tường minh theo bảng dưới đây:
| I/O-bound process | CPU-bound process |
|---|---|
| Chương trình tốn nhiều thời gian để giao tiếp với các thiết bị chậm hơn như kết nối mạng, ổ cứng, máy in | Chương trình tốn thời gian cho các hoạt động của CPU |
| Tăng tốc chương trình đồng nghĩa với việc chồng chéo thời gian chờ ở các thiết bị | Tăng tốc nó liên quan đến việc tìm cách để thực hiện nhiều phép tính hơn trong một khoảng thời gian |
Bắt đầu với I/O-bound.
Synchronize.
Xét ví dụ:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
Trong ví dụ này, hàm download_site download contents của url có sẵn và in ra kích cỡ của contents. Ở đây ta dùng Session object của thư viện request. Dùng Session cho phép chúng ta thực hiện 1 số tricks và tăng tốc chương trình lên thay vì chỉ dùng get().
Sau khi run, ta sẽ được:
.......
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Downloaded 160 in 3.8454935550689697 seconds
threading
Xét ví dụ sau:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
Ở ví dụ này, mỗi thread sẽ tạo cho nó một requests.Session(). Bởi vì HĐH điều khiển khi nào một task interrupt và một task khác bắt đầu, bất kì data nào được shared giữa các threads cũng cần được bảo vệ, gọi là thread-safe. Không may là Session trong requests không phải thread-safe. Nên bạn cần phải tạo Session riêng cho từng thread. Bạn có thể tìm hiểu ở trong issue này.
Có nhiều chiến thuật để làm cho việc truy cập data là thread-safe, tùy thuộc vào data gì và chúng ta sử dụng nó như thế nào. Một trong số đó là thread-safe data structure như Queue trong module queue.
threading.lock đảm bảo rằng chỉ một thread có thể truy cập một đoạn code hay một chút bộ nhớ tại một thời điểm.
threading.local() tạo một object trông giống như global nhưng cụ thể cho mỗi thread riêng lẻ. Trông hơi kì cục nhưng chúng ta chỉ muốn tạo một trong những objects này, không phải một object cho mỗi thread. Bản thân object sẽ đảm nhận việc tách các truy cập từ các threads khác nhau thành các dữ liệu khác nhau.
Khi get_session được gọi, session tìm kiếm thread cụ thể mà nó đang chạy. Vì vậy mỗi thread sẽ tạo một session cho lần đầu nó gọi get_session() và sau đó sẽ dùng session đó cho mỗi cuộc gọi tiếp theo trong suốt thời gian tồn tại của nó.
Ở đây ta dùng 5 thread. Bạn có thể thử với số threads khác nhau nếu muốn nhé.
Sau khi run:
.......
Read 276 from http://olympus.realpython.org/dice
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Read 276 from http://olympus.realpython.org/dice
Read 10490 from https://www.jython.org
Downloaded 160 in 1.1251485347747803 seconds
Nhanh hơn gấp 3 so với chạy tuần tự. Wonderful!!
Các vấn đề có thể xảy ra với threading là race conditions, bạn có thể tham khảo bài viết trước hoặc ví dụ này
asyncio
asyncio basic
Chi tiết tại
Khái niệm chung của asyncio là nó là một Python object, gọi là event-loop, điều khiển khi nào mỗi task chạy và chạy ra sao. Event loop là nhận biết từng task và biết nó đang ở trong trạng thái nào. Trong thực tế, có thể có nhiều trạng thái của task, nhưng trong phạm vi bài viết này mình chỉ trình bày 2 trạng thái cho đơn giản.
Trạng thái sẵn sàng chỉ ra rằng 1 task có công việc để làm và sẵn sàng để chạy. Trạng thái chờ nghĩa là task đang chờ một ngoài thứ bên ngoài hoàn tất, ví dụ như các theo tác network.
Event loop đơn giản của chúng ta duy trì 2 danh sách các tasks, một cho mỗi trạng thái này. Nó chọn một trong các tasks sẵn sàng và bắt đầu chạy. Task đó nằm trong quyền kiểm soát hoàn toàn cho tới khi nó hợp tác trao quyền điều khiển trở lại event loop.
Khi task đang chạy trao quyền điều khiển cho event loop, event loop đặt task đó vào danh sách sẵn sàng hoặc danh sách chờ, sau đó đi qua từng task trong danh sách chờ để xem liệu đã sẵn sàng chưa khi một tác vụ I/O hoàn tất. Nó biết rằng các tasks trong danh sách sẵn sàng vẫn sẵn sàng bởi vì nó biết chúng vẫn chưa chạy.
Một khi tất cả các tasks được sắp xếp vào đúng danh sách, event loop chọn task tiếp theo để chạy và quá trình được tiếp diễn. Event loop của chúng ta chọn task đã chờ đợi lâu nhất và chạy nó. Quá trình này lặp lại cho đến khi kết thúc event loop.
Một điều quan trọng của asyncio là các tasks không bao giờ từ bỏ quyền kiểm soát trừ khi nó cố ý làm như vậy. Nó không bao giờ bị interrupt trong giữa một operation. Nó cho phép share tài nguyên dễ dàng hơn 1 chút so với khi dùng threading. Bạn cũng không cần phải lo lắng về việc làm cho code của mình thread-safe.
Để nói ra đây thì rất dài, cơ bản asyncio trong Python được thiết kế dựa trên generators mà mình sẽ trình bài ở 1 bài viết khác. Bạn có thể
tìm hiểu cách hoạt động của nó trên stack overflow.
async và await
Khi làm việc với asyncio bạn sẽ gặp 2 keyword mới là async và await.
Bạn có thể nhìn await như một magic cho phép task kiểm soát thủ công trở lại event loop. Khi code của bạn await một function call,
nó là một tín hiệu cho biết lời gọi sẽ xảy ra trong một khoảng thời gian và task sẽ từ bỏ quyền kiểm soát.
Đơn giản nhất là nghĩ async như một flag để Python nói rằng function đó chuẩn bị được định nghĩa sử dụng await. Tuy nhiên trong một số trường
hợp điều này không đúng.
Một ngoại lệ là với câu lệnh async with, nó tạo một context manager từ một object bạn sẽ await. Trong khi ngữ nghĩa khác nhau một chút,
nhưng ý tưởng giống nhau là dùng flag cho context manager như vài thứ có thể hoán đổi.
Ở đây sẽ có vài sự phức tạp trong việc quản lý tương tác giữa event loop và tasks, bạn nên đọc documentation từ python.org.
Xem ví dụ sau:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")
Vẫn là ý tưởng cũ nhưng ở đây có một số sự thay đổi trong code.
download_site() dùng async keyword cho việc định nghĩa hàm và trong việc quản lý context manager khi bạn thực sự gọi session.get().
download_all_sites() thay đổi khá nhiều so với những ví dụ trước. Bạn có thể share sessions giữa các tasks với nhau, vì vậy khi session được tạo ở đây như một context manager, các tasks có thể share session bởi vì chúng đang chạy trên cùng một thread giống nhau. Không có cách nào để task có thể ngắt task khác trong khi session ở trạng thái bad state.
Trong context manager đó, nó tạo một list các tasks sử dụng ayncio.ensure_future(), nó cũng trông coi cả việc bắt đầu chúng. Một khi tất cả các tasks được tạo, function đó sử dụng asyncio.gather() để giữ cho sesstion context sống (alive) cho tới khi tất cả các tasks hoàn tất.
Trong ví dụ dùng threading, code cũng làm việc tương tự, nhưng chi tiết được xử lý trong ThreadPoolExecutor.
Một trong những ưu điểm của asyncio là nó có quy mô tốt hơn nhiều so với threading, với threading, nó sẽ giới hạn một số nhất định các threads được tạo. Mỗi task tốn ít tài nguyên hơn và ít thời gian để tạo hơn so với thread.
Sau khi run:
......
Downloaded 160 in 0.5527686790308653 seconds
Sơ đồ thực thi được thể hiện dưới hình sau:
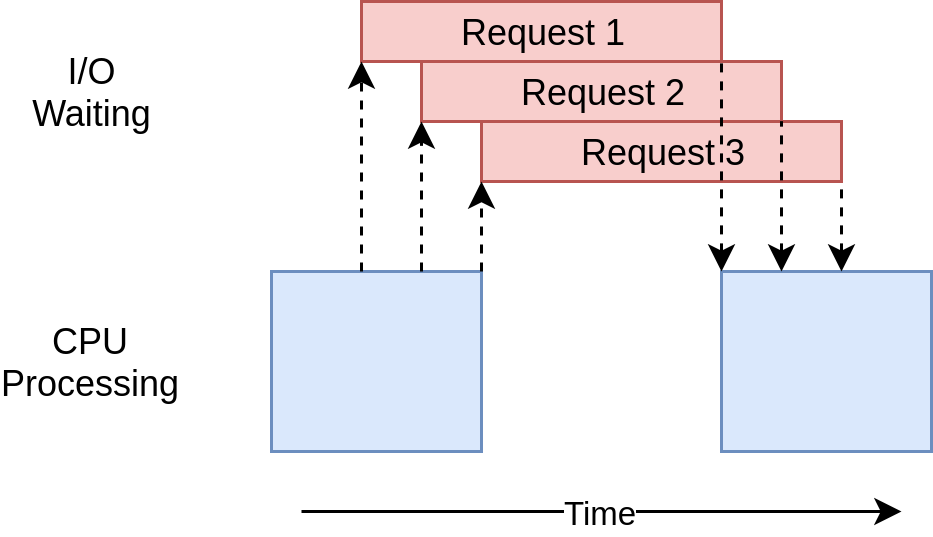
Các vấn đề của asyncio
Ví dụ bạn cần phải có các version async đặc biệt của các thư viện để đạt được full lợi ích của asyncio. Nếu bạn chỉ dùng requests để download các trang web, code có thể chạy chậm hơn vì thư viện này không được thiết kế để thông báo cho event loop rằng nó bị chặn. Tuy nhiên càng ngày sẽ có càng nhiều thư viện chấp nhận sử dụng asyncio vì nó thật sự mang lại khác biệt về hiệu năng với các tác vụ I/O.
Một vấn đề khác là các lợi thế của cooperative multitasking sẽ bị loại bỏ nếu một trong các tasks không hợp tác. Một lỗi nhỏ trong code có thể khiến một task và giữ processor trong một thời gian dài, trong khi các task cần chạy khác "bị bỏ đói". Không có cách nào để event loop đột nhập vào một task nếu task không tự trao quyền kiểm soát lại cho event loop.
Có thể mình sẽ có một bài viết khác sâu hơn về asyncio để tìm hiểu sâu hơn về thư viện này và lợi ích của nó với multi-tasking.
Ở bài viết về processes mình đã trình bày tại sao không nên dùng multiprocessing cho I/O task nên mình sẽ không trình bày ở đây.
Tiếp theo là cách nào để tăng tốc CPU-bound.
Cũng trong bài processes mình cũng đã thử một số ví dụ CPU-bound với
multiprocessing rồi nên cũng sẽ không trình bày lại. Nhìn chung với chương trình thực hiện nhiều việc đòi hỏi CPU bound thì ta
sẽ ưu tiên dùng thư viện multiprocessing hoặc ProcessPoolExecutor trong concurrent.futures.
Khi nào sử dụng concurrency.
Việc đầu tiên của vấn đề này là xác định xem bạn nên sử dụng concurrency module nào. Ví dụ trong bài thì đơn giản, nhưng thực tế khi làm việc với conccurrency trong thực tế sẽ phức tạp hơn rất nhiều và chắn chắn rằng bạn sẽ luôn có bugs trong code. Cho nên, khoan hãy áp dụng concurrency vào chương trình của mình nếu điều đó không thật sự cần thiết, nếu bắt buộc phải dùng thì cần xác định xem loại concurrency nào cần dùng, threading, asyncio hay là multiprocessing.
Một khi đã có quyết định, bạn nên tối ưu chương trình của mình, soi coi chương trình là CPU bound hay I/O bound. CPU-bound thì dùng multiprocessing, I/O bound thì dùng threading hoặc asyncio tùy vào thực tế.
Với chương trình I/O thì có một điều cần lưu ý: "Sử dụng asyncio khi bạn có thể, dùng threading khi bạn bắt buộc phải dùng".
Kết
Bạn đã nắm được các loại concurrency cơ bản trong Python:
- threading
- asyncio
- multiprocessing
Bạn cũng đã nắm được cách thức để sử dụng từng thư viện trong các trường hợp cụ thể.
Mong là những gì được trình bày sẽ có ích cho bạn ít nhiều.
Bài viết mình kết thúc ở đây!
Nguồn
- RealPython
- wikipedia